
At Aurora we believe that self-driving technology will dramatically improve the safety, accessibility, and convenience of transportation. Our mission is to deliver these benefits safely, quickly and broadly. In service of that mission, we wanted to share some of our thinking on how we approach the development of this technology. We wrote much of this for our employees in 2017, and it holds as our technical strategy today. We hope that you find it useful.
Self-driving cars are an applied science problem; not conventional product development. We structure our organization to solve hard science problems and build our partnerships to turn that science into products. We don’t believe in isolated research programs or teams separated from engineering; we believe we need the best engineers locked arms with the best domain specialists and we try to hire the unicorns who are amazing at both. We don’t believe in generic management or engineers as a fungible asset — leaders arise in our organization from deep understanding of how to deliver in an applied science setting.
Incrementalism is broken; long live incrementalism. We believe that an incrementalism where the system gets better across all domains (L2 to L3 to L4) simply doesn’t work. Drivers cannot be inattentively attentive. We will not release a system that misleads drivers about its capabilities and thus raises the already too-high risks of driving.
That said, boiling the ocean remains a bad idea. Instead, our approach to incrementalism identifies key areas that are of high value to society and ensures fully self-driving capability there first, growing our reach outward from areas of mastery.
Don’t test what doesn’t work. One common misconception in this space is that developing a self-driving system is “just about the data”, with the implicit assumption that the team with the most data will win. Our experience suggests this is not the case. Pursuing this view can lead to the generation of tremendous numbers of low-value autonomy miles. Self-driving cars can generate terabytes of data per hour, far more than is useful to process. The teams that don’t thoughtfully scale data pipelines that extract value will drown in data and operational complexity.
Here’s what we do differently:
-
We don’t test what we can’t simulate to work. Simulation may be doomed to succeed, but if code doesn’t work in simulation, it certainly won’t in the real world.
-
We consistently test our code using unit tests, module tests and full system simulation tests before ever testing it on the road.
-
Testing is the first step of reinforcement learning. Failed tests become example problems and constraints on what the system must do — they thus guide both engineering and learning.
Fuel the rockets. An adage we learned years ago says, “Don’t try to build a ladder to the moon”. The phrase came through the old Bell Labs days when convolutional neural networks were first being used to build commercial check-readers — the same technology that has helped transform computer vision into applied machine learning today. The implication is that building a ladder makes small progress each day and is gratifying for engineers. The problem is that it will never practically reach the goal. The way to actually get there is build a rocket, which will initially appear to make little-to-no visible progress and will sit on the pad for a long time. Once carefully built and tested, this rocket will cross the quarter million miles in a matter of days.
Each day we need to balance the immediacy of unblocking progress for our colleagues and partners with the need to fuel the rockets.
Our goal is to launch self-driving vehicles safely and quickly. That means we prefer to craft models and learn their parameters rather then manually tune them. We prefer fast experiments. If we can whip up a prototype in Python (or imperfectly efficient C++), we try that first. Internally, we make a judgement: would a learning system better perform what I’d like to achieve? If so, let’s do it, even though it will take incrementally more time in the short run. We have to fuel those rockets.
Our approach to learning:
-
We learn from experts. We build tools that enable us to collect high-quality annotations. Our experience has been that higher-quality annotations are more important than a larger quantity of lower-quality annotations.
-
We learn from demonstration. We can get tremendously valuable data of how to drive from expert demonstration; we gain even more value from corrections to driving. Interventions indicate both (a) we made a significant mistake to get into this situation, and (b) how to recover from this situation. The first is harder to use, but is tremendously valuable and a large part of our work.
-
We learn from simulation and real-world regression tests. Such scenarios serve as the constraints on our system — we want smooth, predictable, human-like behavior subject to the constraint that the behavior must correctly handle a battery of real-world and simulated cases.
Most of the work in machine learning lies in building the pipelines and infrastructure to support it, so this is where a large share of our early efforts are focused.
Design for learnability. In our software design, our goal is to think carefully about how a given approach will be trained in an existing framework and with reusable pipelines. We avoid building custom learning frameworks, as these add complexity and make building pipelines around them more complex. We should need a good reason not to simply implement and train them in a standard pipeline.
It is often very tricky to build in learning after the fact. Each design effort (document and review) should include whether we think learning is useful or not, and if so, how we will get effective training data. If we don’t think about how to get annotations, or how to encode loss, the resulting system will demand difficult-to-obtain and ambiguous (for labelers) annotations, as well as difficult custom training frameworks.
Consider, as an example, adding state-machine or modal behavior to planning — for instance, a discrete state on “lane changing” or not. Everywhere we can, we’d like to train our driving behavior from a combination of human driving data and then impose constraints as planning invariants (i.e. the SDV should never collide with simulated vehicles even if they are performing extreme maneuvers). We don’t want to have to manually annotate “this motion corresponds to a lane change that began at this point in time”, nor “ignore this pedestrian in your planning”, or other such discrete, special purpose, tasks. We rethink designs that don’t have a reasonable path to train. We believe that those who don’t design for learnability will be left behind.
Perception is a game of statistics. We believe it will ultimately be entirely possible to build a self-driving car that can get by on, for instance, cameras alone. However, getting autonomy out safely, quickly, and broadly means driving down errors as quickly as possible. Crudely speaking, if we have three independent modalities with epsilon miss-detection-rates and we combine them we can achieve an epsilon³ rate in perception. In practice, relatively orthogonal failure modes won’t achieve that level of benefit, however, an error every million miles can get boosted to an error every billion miles. It is extremely difficult to achieve this level of accuracy with a single modality alone.
Different sensor modalities have different strengths and weaknesses; thus, incorporating multiple modalities drives orders of magnitude improvements in the reliability of the system. Cameras suffer from difficulty in low-light and high dynamic range scenarios; radars suffer from limited resolution and artifacts due to multi-path and doppler ambiguity; lidars “see” obscurants. The images below show real examples from Aurora’s system while it was driving autonomously.

Cameras have limited dynamic range, making detection difficult.

Tunnels create a multi-path nightmare scenario for radar sensors.
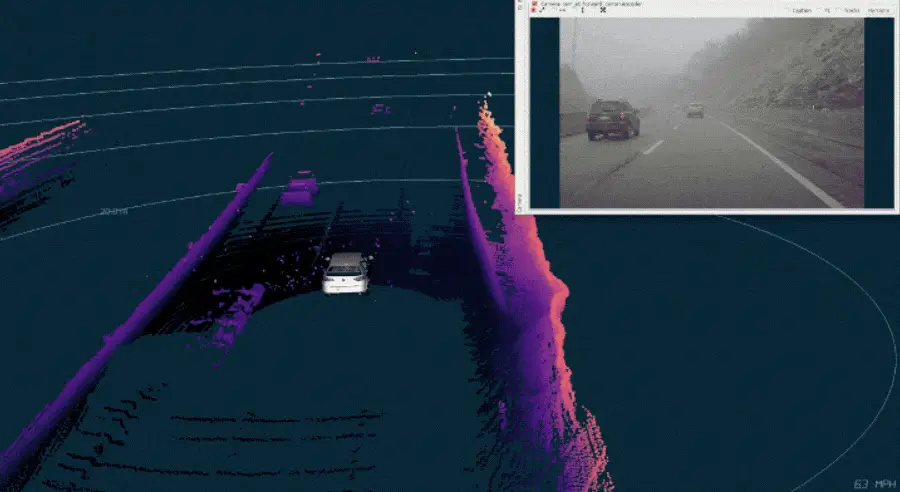
Lidar is sensitive enough to detect snow, making it more difficult to identify important objects.
Maps make everything better. Just as humans are better drivers when they’ve been somewhere before, our system leverages knowledge gained from previous drives. We are building a series of safety measures which identify changes in this information and will ultimately allow vehicles to adapt before maps are updated. Moreover, we’ve designed our Atlas mapping system to be extremely fast to update with minimal data gathering and computation.
Why not forego maps altogether? Again, statistics — if a system only has to handle changes relative to the map 1% of the time, we can be up to two orders of magnitude safer then one that must always rely on only its real-time perceptions of the world.
Engineering excellence over dogma. We pride ourselves on being a team that can design and build with rigor. When we have a problem for which a reliable engineering process exists, we build the best version of that. We don’t believe that end-to-end learning will solve all problems. We do believe that the problem of self-driving demands a disciplined approach that carefully weaves together the best of modern machine learning with rigorous engineering, including, for instance, real-time systems, geometry, state estimation, high-performance, reliable, and scalable infrastructure, and decision making and control techniques.
Our goal is to thoughtfully combine the best of these approaches throughout, in an effort to achieve high-performance perception and a planning systems that maintain safety invariants while achieving predictable and human-like driving.

Aurora’s perception system tracking cyclists in a parking lot.
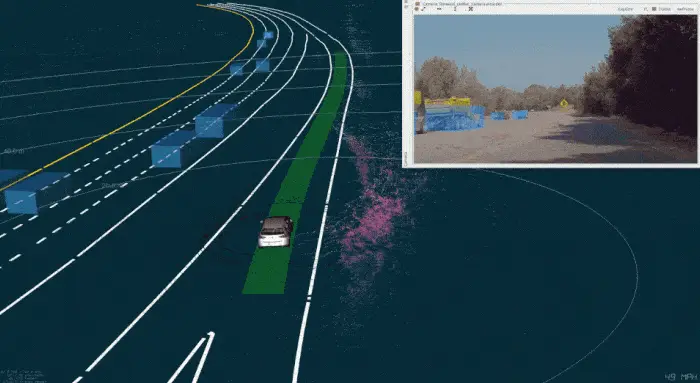
Aurora’s machine learned merging algorithm choosing to slot comfortably during a freeway merge.

Aurora’s perception system tracking a lane-splitting motorbike.
We care about review processes, we care about high quality, common-ownership of code, we favor extensive automation in testing, and we work hard to build scalable, reproducible analysis tools. We don’t stand on ceremony — we run experiments fast. When they work, we turn them into reliable code. When they don’t we go back to the drawing board.
None of these careful processes is necessarily novel, in fact that’s part of the point. We’ve learned a lot of lessons through the years. About what works and what doesn’t. About where the technology is headed and how to avoid future challenges to scalability of the solution.
We’re making a fresh start at building the driver by combining excellence in AI, rigorous engineering and a team with decades of experience building robots that work. Together we will deliver self-driving vehicles safely, quickly and broadly.
Welcome to the team,
Chris, Drew & Sterling
{kind=link}